Your comments
@Barney - My thinking regarding your concern is - we can always delete a populated step, if needed (we don't do this a lot to be honest - for the sake of accurate / quality tests), once everything has loaded & populated on the test editor page?
Hint - the debut output where we generate the test from has all the variables, objects and / or recordsets - inputs and outputs for all the workflows including the child workflows - can all the variables, objects and / or recordsets not be populated, instead of just the inputs / outputs of the Main or targeted workflow?
Please mark as complete - had a discussion with Sehul and it looks like the current SQL Tool will allow this
Pls mark ticket as completed
This was resolved by Yogesh and Sehul - this behaviour is by design when filling the OnError variable in a workflow it will suppress the error and continue as normal - Pls mark ticket as completed
Resolved by Yogesh in version 2.4.10 - Pls close ticket
Resolution: Populate the OnError variable of the Main SubWorkflow on the consume workflow. This will force a 200 OK response, even if an error (like an API failure) happens in the sub-workflow.
This fix has been implemented in Journeys and no queues have stopped in the past 3 weeks.
This fix was later rolled out to other MicroServices such as Collections, BusinessRules etc
I believe this resolves one of the main issues why we switch architecture back to VMs
Ticket resolved
Regards,
W
Context: Morning Everyone
We have a big problem in Journey Team’s Production environment, and we please need your assistance / guidance as to how we can resolve it.
Context:
When we read a record from RabbitMQ, and that record gets consumed in a workflow, and an error occurs in the workflow, like an API error, we would handle the error inside the workflow (pack up with a status of lost), however, the response sent back to Rabbit is not a 200 OK, even though we handled the error, but some other response like 400 Bad Request. Now what happens is Rabbit receives this back as an unack.
Now if we have 7 consumers each with a prefetch of 5, we thus have a read capacity of 35 messages. But what happens over a period of a day or so is that the unacks build up (due to API errors in the workflows) until we have 35 unacks on the queue. What happens then, because our 35 read capacity is now stuck with 35 unacks, the queue is not being processed further. What we used to do is to restart Warewolf, and it would take the 35 in unack and put them back in Ready and the queue would proceed with processing.
Now, here is where the problem comes in – we recently upgraded to Warewolf 2.4.8.0, as it contained some additional logic for RabbitMQ hoping that it would bring some kind of relief for the issue. However, we now see that with this version, even if we restart Warewolf, the unack messages on the queue still remain at 35 (it doesn’t put it in Ready like the previous versions), thus we do not have any capacity to read from the queue and the queue is stuck. This is currently happening on a number of queues.
We have a legal risk to the business here – as we are not serving our customers. How can we resolve this?
A downgrade was mentioned as an option to bring immediate relief – do you agree? If yes, to what version? And how do we remedy this for the future?
Finally – this kind of issue became more apparent after a change was made in Warewolf on how to deal with errors – I think the change was introduced at 2.8.2.1
Update:
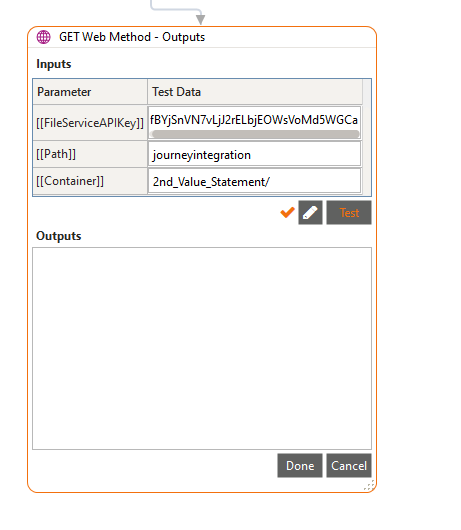
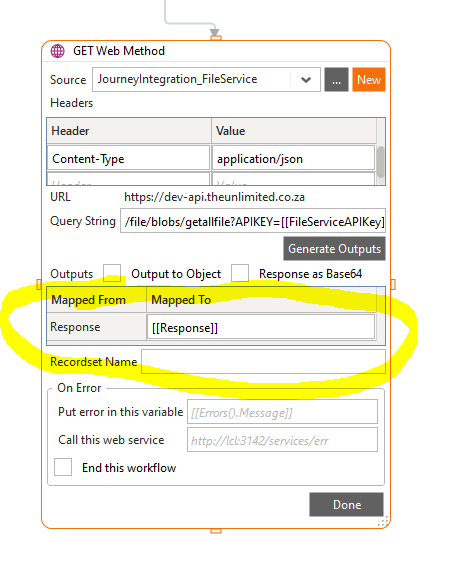
When Output is blank in Warewolf 2.8.4.0, the variable maps, for example:
Customer support service by UserEcho


Please note, we experienced this on Warewolf version 2.8.6.16. Tested by 2 different developers. I then downgraded to version 2.8.1.3 and experienced similar behaviour.