Queue Consumers failing when error in payload
Service is launched successfully and consumers connected to queues. However, after around an hour or so we would find that the consumers on the journey.welcome.request queue would disappear however the other journey queue were reflecting the consumers fine.
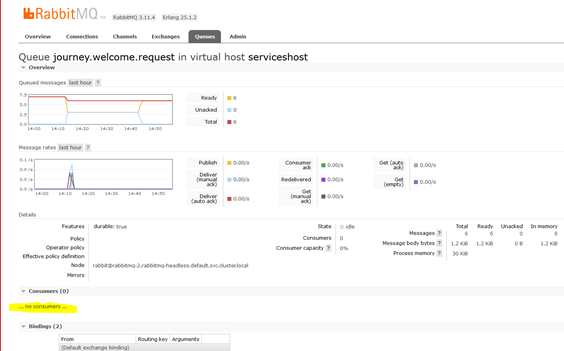
What we found was the queue worker process would die (as per screenshot) the only way to get the consumers back was to restart the warewolf server service
2023-04-21 12:49:07,354 INFO - [00000000-0000-0000-0000-000000000000] - Trigger restarting '05c7daf0-3a79-410e-b101-0c9addf63136'
2023-04-21 12:49:07,573 INFO - [WarewolfLogger.exe] - Logging Server OnError, Error details:Unable to read data from the transport connection: An existing connection was forcibly closed by the remote host.
2023-04-21 12:49:07,573 INFO - [WarewolfLogger.exe] - 4/21/2023 12:49:07 PM [Debug] Error while reading System.IO.IOException: Unable to read data from the transport connection: An existing connection was forcibly closed by the remote host. ---> System.Net.Sockets.SocketException: An existing connection was forcibly closed by the remote host
2023-04-21 12:49:07,573 INFO - [WarewolfLogger.exe] - at System.Net.Sockets.Socket.EndReceive(IAsyncResult asyncResult)
2023-04-21 12:49:07,573 INFO - [WarewolfLogger.exe] - at System.Net.Sockets.NetworkStream.EndRead(IAsyncResult asyncResult)
2023-04-21 12:49:07,573 INFO - [WarewolfLogger.exe] - --- End of inner exception stack trace ---
2023-04-21 12:49:07,573 INFO - [WarewolfLogger.exe] - at System.Net.Sockets.NetworkStream.EndRead(IAsyncResult asyncResult)
2023-04-21 12:49:07,573 INFO - [WarewolfLogger.exe] - at System.Threading.Tasks.TaskFactory`1.FromAsyncCoreLogic(IAsyncResult iar, Func`2 endFunction, Action`1 endAction, Task`1 promise, Boolean requiresSynchronization)
2023-04-21 12:49:07,588 INFO - [Warewolf Info] - queue process died: Journey Start Trigger(05c7daf0-3a79-410e-b101-0c9addf63136)
2023-04-21 12:49:07,729 ERROR - [ at System.Diagnostics.Process.Kill()
What we tried to do was to increase the concurrency to 3 and set the prefetch to 1, and we still experienced the same issue
On deeper investigation it appeared that if the message being process was unable to reach the external api’s for any reason for instance the product api, it would kill the consumers, we tested this by correlating the timelines of when the “product” api was available to when the consumers disappear.
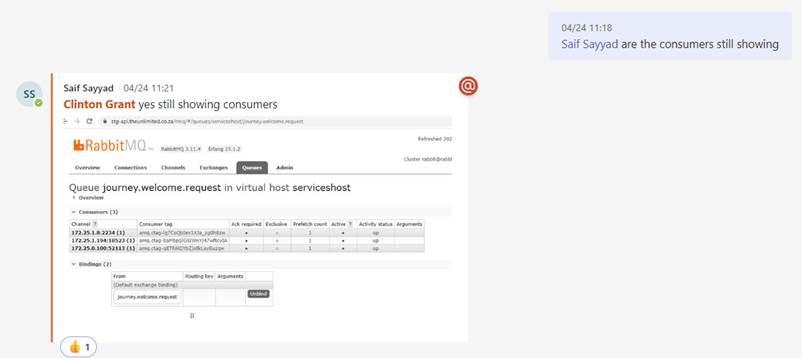
Once we had the “product” api stabilized consumers were stable and remained present
So appears to be a bug with the queue worker when it is unable to process the message correct caused this to crash
My understanding of this is:
- Error was experienced during processing of the message
- That message which is an unack message with the error did not leave RabbitMQ due to the fact that it never received an ack back from warewolf.
- RabbitMQ did not allow additional messages to be processed due to not receiving the ack back (aka message stuck)
- Appear to be the way that warewolf error handling works where it does not send through the ack even if an error was experienced with the message.
Customer support service by UserEcho

This is a nice breakdown, thanks Khonzi.
I've been thinking about the issue, and from my experience monitoring journeys and the particular issue, I have the following comments:
1. If an API fails, the current condition in the Decision Tool, "If there is No error", appears to not not work for certain errors like a 504 error. What then happens the customer record gets stuck in the Journey, because it doesn't pack up - due to the logic in the decision failing. Now, because the record is stuck in the journey, it doesn't send an acknowledgement back to the relevant RabbitMQ queue. And because this happens, the next record in the RabbitMQ queue is not being read and processed - we basically have a lock, that only a restart at this stage seems to resolve.
Now knowing what we know, what can we do differently?
2. We can fix the condition, "If there is no errors" in the Decision Tool to recognize failures such as 504.
or
From the Journey Team - We can alter the condition on the Decision Tool, to rather look if any records are being returned from the API, instead of "If there is no error". If no records are returned then Packup, else continue.
3. We can also implement ASYNC processing on the journeys - this will enable other records to be processed without having to wait for one to finish before the next one is picked up.
The decision tool needs to be fixed. Have you logged that bug?
You should always process in ASYNC when the architecture allows it.
Hi @Barney,
I've logged the following ticket - https://community.warewolf.io/communities/1/topics/1510-can-we-please-confirm-that-the-condition-if-there-is-no-error-on-the-decision-tool-recognizes-and
With regards to ASYNC processing, we've removed it after we experienced a drop-off in records during execution. I'm aware that you have reported it and DEV2 have fixed it, we (Journey Team) haven't enabled or tested it since the fix was made. Something for us to look into.
Context: Morning Everyone
We have a big problem in Journey Team’s Production environment, and we please need your assistance / guidance as to how we can resolve it.
Context:
When we read a record from RabbitMQ, and that record gets consumed in a workflow, and an error occurs in the workflow, like an API error, we would handle the error inside the workflow (pack up with a status of lost), however, the response sent back to Rabbit is not a 200 OK, even though we handled the error, but some other response like 400 Bad Request. Now what happens is Rabbit receives this back as an unack.
Now if we have 7 consumers each with a prefetch of 5, we thus have a read capacity of 35 messages. But what happens over a period of a day or so is that the unacks build up (due to API errors in the workflows) until we have 35 unacks on the queue. What happens then, because our 35 read capacity is now stuck with 35 unacks, the queue is not being processed further. What we used to do is to restart Warewolf, and it would take the 35 in unack and put them back in Ready and the queue would proceed with processing.
Now, here is where the problem comes in – we recently upgraded to Warewolf 2.4.8.0, as it contained some additional logic for RabbitMQ hoping that it would bring some kind of relief for the issue. However, we now see that with this version, even if we restart Warewolf, the unack messages on the queue still remain at 35 (it doesn’t put it in Ready like the previous versions), thus we do not have any capacity to read from the queue and the queue is stuck. This is currently happening on a number of queues.
We have a legal risk to the business here – as we are not serving our customers. How can we resolve this?
A downgrade was mentioned as an option to bring immediate relief – do you agree? If yes, to what version? And how do we remedy this for the future?
Finally – this kind of issue became more apparent after a change was made in Warewolf on how to deal with errors – I think the change was introduced at 2.8.2.1
Resolution: Populate the OnError variable of the Main SubWorkflow on the consume workflow. This will force a 200 OK response, even if an error (like an API failure) happens in the sub-workflow.
This fix has been implemented in Journeys and no queues have stopped in the past 3 weeks.
This fix was later rolled out to other MicroServices such as Collections, BusinessRules etc
I believe this resolves one of the main issues why we switch architecture back to VMs
Ticket resolved
Regards,
W